 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Deep Hierarchical Variational Autoencoder for Voice Conversion
Dec 06, 2021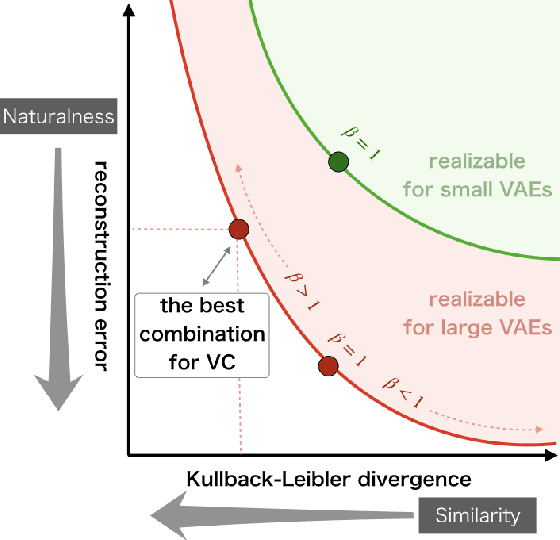
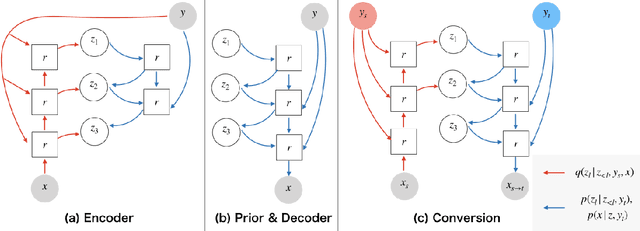
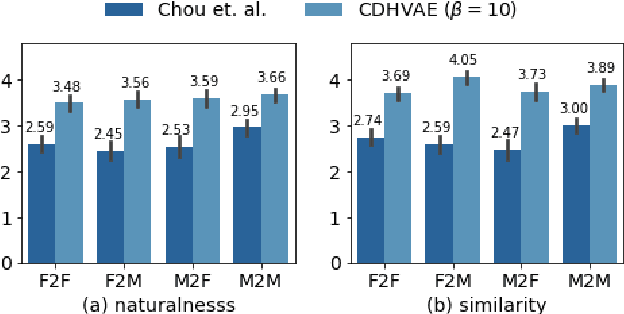
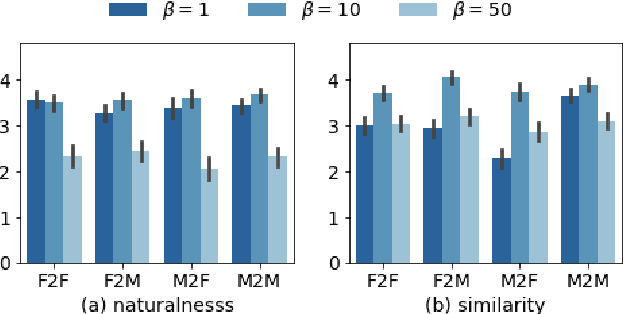
Variational autoencoder-based voice conversion (VAE-VC) has the advantage of requiring only pairs of speeches and speaker labels for training. Unlike the majority of the research in VAE-VC which focuses on utilizing auxiliary losses or discretizing latent variables, this paper investigates how an increasing model expressiveness has benefits and impacts on the VAE-VC. Specifically, we first analyze VAE-VC from a rate-distortion perspective, and point out that model expressiveness is significant for VAE-VC because rate and distortion reflect similarity and naturalness of converted speeches. Based on the analysis, we propose a novel VC method using a deep hierarchical VAE, which has high model expressiveness as well as having fast conversion speed thanks to its non-autoregressive decoder. Also, our analysis reveals another problem that similarity can be degraded when the latent variable of VAEs has redundant information. We address the problem by controlling the information contained in the latent variable using $\beta$-VAE objective. In the experiment using VCTK corpus, the proposed method achieved mean opinion scores higher than 3.5 on both naturalness and similarity in inter-gender settings, which are higher than the scores of existing autoencoder-based VC methods.
Investigating context features hidden in End-to-End TTS
Nov 04, 2018



Recent studies have introduced end-to-end TTS, which integrates the production of context and acoustic features in statistical parametric speech synthesis. As a result, a single neural network replaced laborious feature engineering with automated feature learning. However, little is known about what types of context information end-to-end TTS extracts from text input before synthesizing speech, and the previous knowledge about context features is barely utilized. In this work, we first point out the model similarity between end-to-end TTS and parametric TTS. Based on the similarity, we evaluate the quality of encoder outputs from an end-to-end TTS system against eight criteria that are derived from a standard set of context information used in parametric TTS. We conduct experiments using an evaluation procedure that has been newly developed in the machine learning literature for quantitative analysis of neural representations, while adapting it to the TTS domain. Experimental results show that the encoder outputs reflect both linguistic and phonetic contexts, such as vowel reduction at phoneme level, lexical stress at syllable level, and part-of-speech at word level, possibly due to the joint optimization of context and acoustic features.